The Dasher concept works with almost any language. Several European languages and Japanese are currently supported in Dasher. To make use of Dasher with a non-English European language, you need to train Dasher with a text file full of natural writing in your language - put this file in the location input/source or input/source.txt. Make sure the "Word" option is switched off, or else replace the file input/dict with a dictionary for your language.
When version 3 is released, we plan to greatly increase the number of languages handled in Dasher, with the help of the Open Source community. [Version 3 will work in Unicode.] With version 3, as with version 1.6, every language will require a text file full of natural writing (about 300K or more).
More advice about how to create a training set
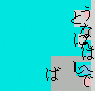
The Japanese name for Dasher is
Daishoya (![]() ),
which means `scribe'.
),
which means `scribe'.
|
|
| A movie describing Daishoya in Japanese. |
|
|
As a first step towards a full Japanese version of Dasher handling both Kana and Kanji, David Ward has written a Hiragana version, available in version 1.6.3 of Dasher. (NB: later versions of windows-Dasher, such as 1.6.8, do not support Hiragana, because of Tcl font problems; the linux version of 1.6.8 works fine in Hiragana.)
The conversion of Dasher to Daishoya is simple: we replace the English alphabet
a..z by the Hiragana alphabet, ![]() (a,i,u,e,o, ka,ki,ku,ke,ko,...); and
we replace the English training text by a Hiragana document. [Unfortunately,
we have not been able to find a large pure-Hiragana document, so
our language model is not as well-trained as we would like.]
(a,i,u,e,o, ka,ki,ku,ke,ko,...); and
we replace the English training text by a Hiragana document. [Unfortunately,
we have not been able to find a large pure-Hiragana document, so
our language model is not as well-trained as we would like.]
Two orderings of the Hiragana alphabet are available (options "japan1"
and "japan2"). In "japan2" the diacritical marks (",o) are
included as separate characters; in "japan1" they are integrated
by including the characters ![]() , etc. in the alphabet ("pa", "ba").
, etc. in the alphabet ("pa", "ba").
We would welcome collaborators to help test Daishoya and introduce it to a large population of users.
We also need Hiragana data, in text form, for training the language model.